
Hoe zet je al die duizelingwekkende coronacijfers in grafieken? Ik krijg geregeld mails van lezers die klagen over een grafiek die ze ergens hebben gezien. Er gaat inderdaad heel wat mis, bijvoorbeeld het in één grafiek direct vergelijken van totale aantallen besmettingen tussen landen, waarbij het ene land 17 miljoen inwoners heeft en het andere 1,4 miljard. Het is dan bijvoorbeeld veel eerlijker om de besmettingen per 100.000 inwoners te vergelijken.
Achter alle coronagrafieken die vrijwel elke dag in deze krant staan, zitten allerlei kleine keuzen die veel uitmaken voor hoe mensen de grafieken lezen. En vaak is helemaal niet zo duidelijk wat de beste keuzen zijn. Als je het verloop van de pandemie in verschillende landen laat zien, begin je dan overal op dezelfde datum, of start je per land op het moment dat de uitbraak daar begon? Ik zou zelf het tweede doen, maar voor het eerste is ook wel iets te zeggen.
Een veel fundamentelere keuze is de vraag welke soort schaal je gebruikt voor iets dat exponentieel groeit, zoals een corona-uitbraak. Veel data-experts en handboeken vinden dat je bij dit soort snel stijgende data een logaritmische schaal moet gebruiken waarbij intervallen op de y-as steeds groter worden. Hieronder staat bijvoorbeeld het totaal aantal coronabesmettingen per 100.000 inwoners in vier landen op zo’n logaritmische schaal.
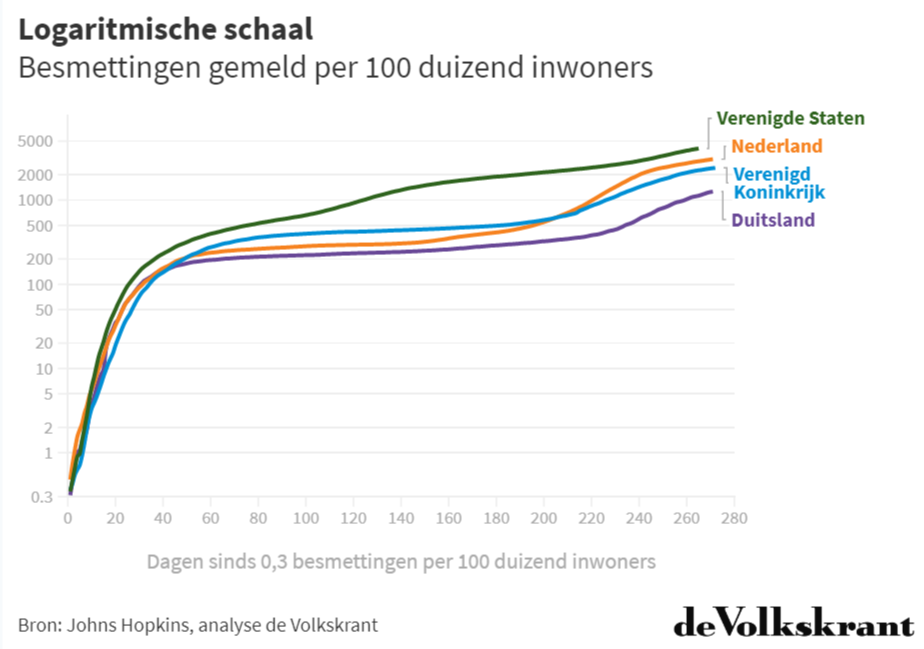
Wat kun je op basis van deze grafiek zeggen over de ontwikkelingen in deze vier landen de laatste weken? Niet zo veel eigenlijk, het zit allemaal nogal op elkaar gepakt. Hieronder zie je ook dezelfde gegevens, maar nu op een ‘gewone’, lineaire schaal.
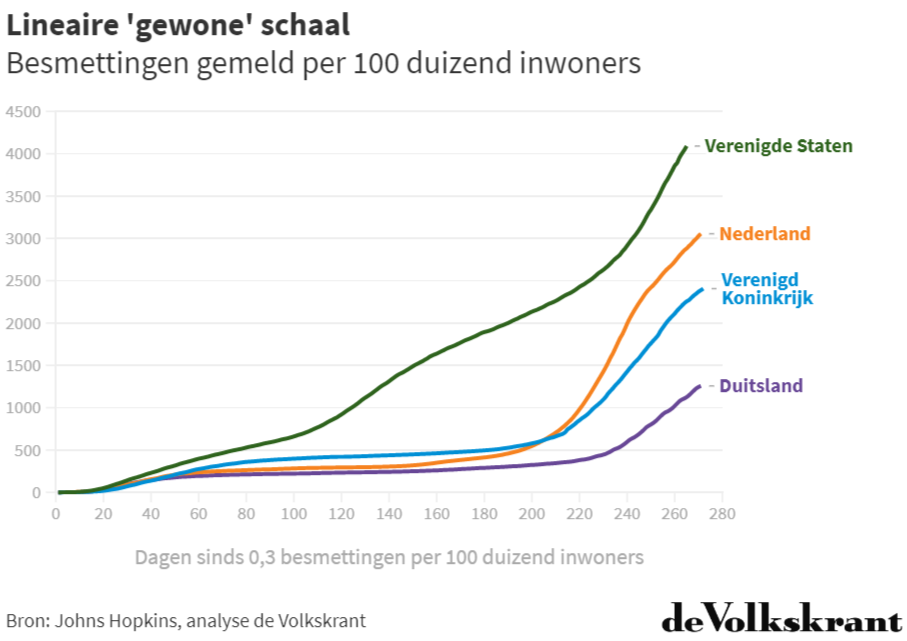
Persoonlijk vind ik deze grafiek een stuk makkelijker te interpreteren. En ik ben niet de enige. Een recente Amerikaanse studie liet zien dat mensen die coronagrafieken kregen op een logaritmische in plaats van een lineaire schaal, veel meer moeite hadden met het aflezen in welke week de grootste stijging was en het realistisch voorspellen van hoe de pandemie zich op korte termijn zou ontwikkelen.
Kortom: het is jammer voor de data-experts en handboeken, maar de lineaire schaal wint het dus in dit geval. Het gaat er bij dit soort keuzen namelijk niet om wat experts de beste manier vinden om de data te laten zien, het gaat er om hoe lezers het makkelijkst de informatie die ze nodig hebben uit een grafiek kunnen halen.
Deze column verscheen op 4 december 2020 in de Volkskrant.